

Table of Contents
Using ChatGPT vs Gemini
Introduction
I recently participated in a company hackathon where the challenge was to create a work-related system incorporating AI. My goal was to develop a deep learning neural network for a new feature in our system. Since the feature was new, we needed to generate training data. Given the tight three-day timeframe, we utilized Large Language Models (LLMs) to produce thousands of data points, which we then manually pruned.
During this data generation phase, my colleagues and I had a productive discussion comparing ChatGPT Plus and Gemini Pro. I've been using ChatGPT Plus for several months, but a friend suggested that Gemini Pro might be better suited for our development and coding tasks. This conversation sparked an idea.
Why not try Gemini Pro for a month and see how it performs? After all, I'm always looking for ways to streamline my work, and if switching LLM providers can enhance my productivity, I'm willing to give it a shot.
In this article, I will share my experience using Gemini Pro for one month and compare it to my experience with ChatGPT Plus. I conducted this experiment while my ChatGPT Plus subscription was still active (until June 10), which allowed me to make a direct comparison between the two platforms before transitioning exclusively to Gemini Pro.
Before we begin, though, I am quite aware of other LLM providers such as Anthropic, and I have actually tried them in the past as well. Although the claim that one LLM produces better code than another is subjective, I do not primarily use LLMs to generate entire codebases, but rather just snippets when needed. I mostly use LLMs at work to proofread what I have wrote, or to generate or convert code from one format to another (such as converting JSON data to a Mermaid Diagram), so I will be reflecting on my experience based on that.
Granted, I also use ChatGPT for a little creative work. Specifically, for generating avatars from an old-school game I play named Fallen Sword, and occasionally to help friends create 10-15 second videos for their Dungeons & Dragons scenarios. I will also include these creative features that the two offer in my comparison.
Code Generation
I use LLMs quite extensively, from bootstrapping drafts from bullet points for a proposal to converting one piece of code to another.
For instance, I tend to use LLMs to ease my visualization work, where I convert JSON into a UML class diagram.
I do this by sending the LLM anonymized JSON data resembling what I want to visualize, then ask it to convert this to MermaidChart syntax, and then make small edits to adjust it to what I want to present to my peers.
To make my example more concrete, here is a sample JSON I anonymized:
{
"data_field_001": "XYZ",
"data_field_002": "anonymizedcustomer",
"data_field_003": "testenv",
"data_field_004": "www.exampleretailer.com",
"data_field_005": "exampleretailer.com",
"data_field_006": "Generic Product Model X - Color",
"entity_A": {
"id_a1": 101,
"id_a2": 11,
"uuid_a1": "a1b2c3d4-e5f6-7890-1234-567890abcdef",
"code_a1": "A1B",
"name_a1": "GenericBrand",
"type_a1": "OWNED",
"flag_a1": true
},
"entity_B": {
"id_b1": 201,
"ref_id_b1": 101,
"uuid_b1": "b2c3d4e5-f6a7-8901-2345-67890abcdef0",
"name_b1": "exampleretailer.com | Generic Product Model X - Color",
"extras_b1": {
"custom_b1_prop1": null,
"custom_b1_prop2": null,
"model_b1": "GN-XYZ-1000",
"internal_ref_b1": {
"ref_code_b1_1": "ANON001",
"ref_code_b1_2": "ANON002",
"ref_id_b1_1": 31
}
},
"flag_b1": true,
"op_b1": "update"
},
"entity_C": {
"id_c1": 301,
"ref_id_c1": 31,
"ref_id_c2": 201,
"item_code_c1": "XYZABCODYYYYMMDDHHMMSS123456789",
"name_c1": "Generic Product Model X - Color",
"url_c1": "https://www.exampleretailer.com/category/product/generic-product-model-x/item12345",
"extras_c1": {
"custom_c1_prop1": null,
"value_c1": 99.99,
"media_flag_c1": "ON",
"content_flag_c1": "ON"
},
"op_c1": "update",
"flag_c1": true
},
"entity_D": {
"id_d1": 401,
"ref_id_d1": 11,
"name_d1": "Generic Category",
"type_d1": "TYPE"
},
"link_entity_A": {
"id_la1": 501,
"ref_id_la1": 401,
"ref_id_la2": 201
},
"media_collection_A": {
"delete_refs_a1": [
701
],
"insert_items_a1": [
{
"id_mia1": 702,
"ref_id_mia1": 201,
"url_mia1": "https://assets.examplecloudstorage.com/api/assetstorage/anon-uuid-container/Resource",
"type_mia1": "IMAGE",
"extras_mia1": {
"timestamp_mia1_1": "2023-01-01T10:00:00",
"timestamp_mia1_2": "2023-01-15T14:30:00",
"name_mia1": "generic_product_image_01.jpg",
"size_mia1": 250000
}
}
]
},
"rules_collection_A": [
{
"id_rca1": 801,
"type_rca1": "product_custom",
"extras_rca1": {
"keywords_rca1": {
"lang_code_1": []
}
},
"ref_id_rca1": 201
},
{
"id_rca1": 802,
"type_rca1": "product_description",
"extras_rca1": {
"keywords_rca1": {
"lang_code_1": [
[
"ANONYMIZED FEATURE 1"
],
[
"EXTENDED BATTERY LIFE"
],
[
"DURABLE AND FOLDABLE"
],
[
"CUSTOMIZABLE BUTTON"
],
[
"WIRELESS CHARGING SUPPORT"
]
]
}
},
"ref_id_rca1": 201
},
{
"id_rca1": 803,
"type_rca1": "product_title",
"extras_rca1": {
"keywords_rca1": {
"lang_code_1": [
[
"GenericBrand"
],
[
"Generic Model X",
"Model X"
],
[
"Color"
],
[
"AccessoryType"
],
[
"CategoryName",
"CATEGORYNAME"
]
]
}
},
"ref_id_rca1": 201
},
{
"id_rca1": 804,
"type_rca1": "regulatory_compliance",
"extras_rca1": {
"flag_rca1": false
},
"ref_id_rca1": 201
}
],
"data_field_007": "AnonymizedCustomerTestEnv",
"data_field_008": "UserXYZ123"
}
This JSON data contains multiple nested fields, and some of them even go three levels deep. In my testing, I usually have fewer problems with Gemini than with ChatGPT. I did not fully test every model but only tested with the models that have the highest level of reasoning available: Gemini 2.5 Pro and o3 from ChatGPT.
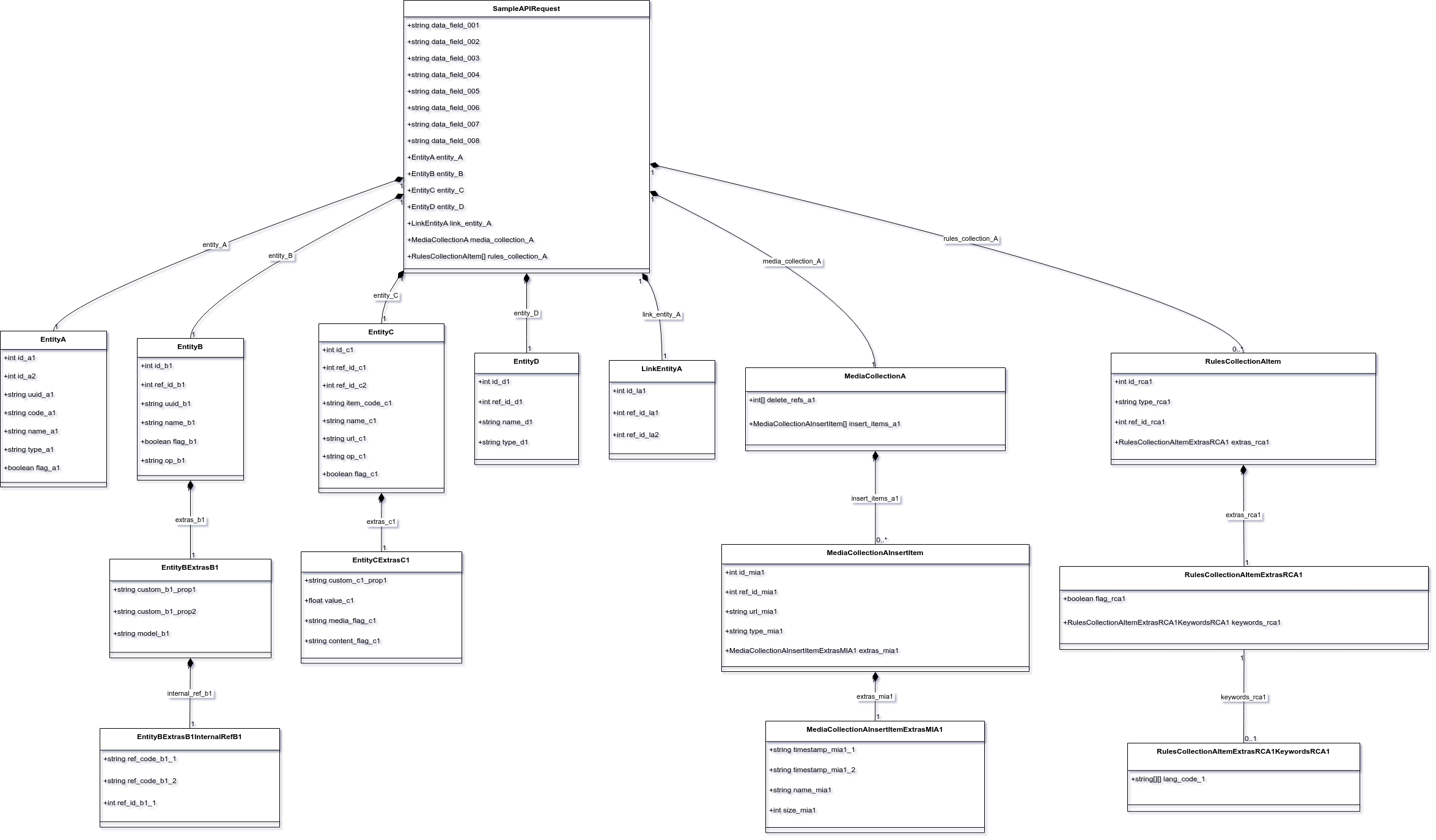
classDiagram
class SampleAPIRequest {
+string data_field_001
+string data_field_002
+string data_field_003
+string data_field_004
+string data_field_005
+string data_field_006
+string data_field_007
+string data_field_008
+EntityA entity_A
+EntityB entity_B
+EntityC entity_C
+EntityD entity_D
+LinkEntityA link_entity_A
+MediaCollectionA media_collection_A
+RulesCollectionAItem[] rules_collection_A
}
class EntityA {
+int id_a1
+int id_a2
+string uuid_a1
+string code_a1
+string name_a1
+string type_a1
+boolean flag_a1
}
class EntityB {
+int id_b1
+int ref_id_b1
+string uuid_b1
+string name_b1
+boolean flag_b1
+string op_b1
}
class EntityBExtrasB1 {
+string custom_b1_prop1
+string custom_b1_prop2
+string model_b1
}
class EntityBExtrasB1InternalRefB1 {
+string ref_code_b1_1
+string ref_code_b1_2
+int ref_id_b1_1
}
class EntityC {
+int id_c1
+int ref_id_c1
+int ref_id_c2
+string item_code_c1
+string name_c1
+string url_c1
+string op_c1
+boolean flag_c1
}
class EntityCExtrasC1 {
+string custom_c1_prop1
+float value_c1
+string media_flag_c1
+string content_flag_c1
}
class EntityD {
+int id_d1
+int ref_id_d1
+string name_d1
+string type_d1
}
class LinkEntityA {
+int id_la1
+int ref_id_la1
+int ref_id_la2
}
class MediaCollectionA {
+int[] delete_refs_a1
+MediaCollectionAInsertItem[] insert_items_a1
}
class MediaCollectionAInsertItem {
+int id_mia1
+int ref_id_mia1
+string url_mia1
+string type_mia1
+MediaCollectionAInsertItemExtrasMIA1 extras_mia1
}
class MediaCollectionAInsertItemExtrasMIA1 {
+string timestamp_mia1_1
+string timestamp_mia1_2
+string name_mia1
+int size_mia1
}
class RulesCollectionAItem {
+int id_rca1
+string type_rca1
+int ref_id_rca1
+RulesCollectionAItemExtrasRCA1 extras_rca1
}
class RulesCollectionAItemExtrasRCA1 {
+boolean flag_rca1
+RulesCollectionAItemExtrasRCA1KeywordsRCA1 keywords_rca1
}
class RulesCollectionAItemExtrasRCA1KeywordsRCA1 {
+string[][] lang_code_1
}
SampleAPIRequest "1" *-- "1" EntityA : entity_A
SampleAPIRequest "1" *-- "1" EntityB : entity_B
SampleAPIRequest "1" *-- "1" EntityC : entity_C
SampleAPIRequest "1" *-- "1" EntityD : entity_D
SampleAPIRequest "1" *-- "1" LinkEntityA : link_entity_A
SampleAPIRequest "1" *-- "1" MediaCollectionA : media_collection_A
SampleAPIRequest "1" *-- "0..*" RulesCollectionAItem : rules_collection_A
EntityB "1" *-- "1" EntityBExtrasB1 : extras_b1
EntityBExtrasB1 "1" *-- "1" EntityBExtrasB1InternalRefB1 : internal_ref_b1
EntityC "1" *-- "1" EntityCExtrasC1 : extras_c1
MediaCollectionA "1" *-- "0..*" MediaCollectionAInsertItem : insert_items_a1
MediaCollectionAInsertItem "1" *-- "1" MediaCollectionAInsertItemExtrasMIA1 : extras_mia1
RulesCollectionAItem "1" *-- "1" RulesCollectionAItemExtrasRCA1 : extras_rca1
RulesCollectionAItemExtrasRCA1 "1" -- "0..1" RulesCollectionAItemExtrasRCA1KeywordsRCA1 : keywords_rca1
Gemini got most of it correct, as seen in the figure above, although it had problems interpreting the content within extras_rca1 of rules_collection_A. For instance, Gemini somehow conveniently dropped keywords_rca1. If it were me, I would create two objects to represent the differing structures for extras_rca1 and then wrap them in a Union clause.
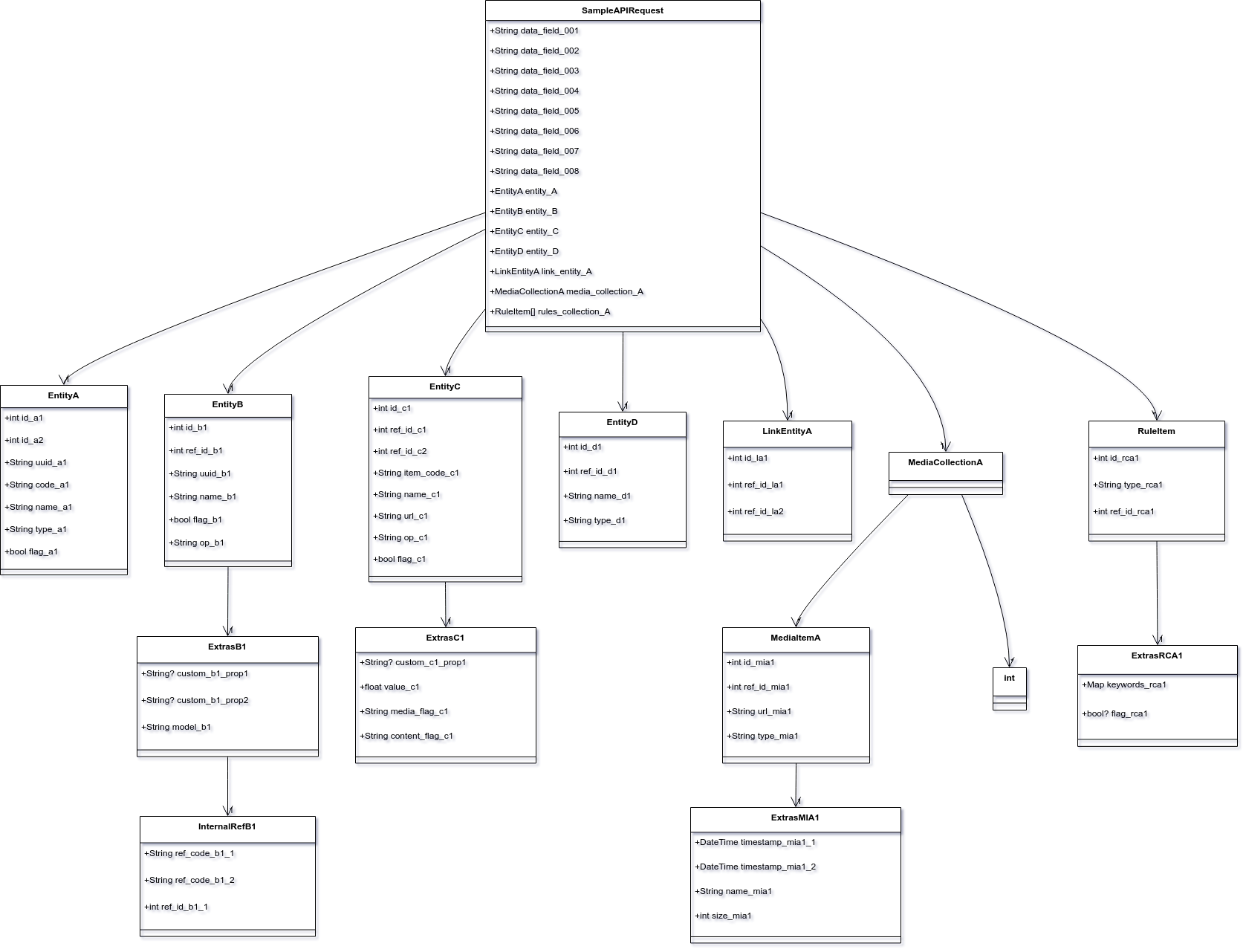
classDiagram
class SampleAPIRequest {
+String data_field_001
+String data_field_002
+String data_field_003
+String data_field_004
+String data_field_005
+String data_field_006
+String data_field_007
+String data_field_008
+EntityA entity_A
+EntityB entity_B
+EntityC entity_C
+EntityD entity_D
+LinkEntityA link_entity_A
+MediaCollectionA media_collection_A
+RuleItem[] rules_collection_A
}
SampleAPIRequest --> "1" EntityA
SampleAPIRequest --> "1" EntityB
SampleAPIRequest --> "1" EntityC
SampleAPIRequest --> "1" EntityD
SampleAPIRequest --> "1" LinkEntityA
SampleAPIRequest --> "1" MediaCollectionA
SampleAPIRequest --> "*" RuleItem
class EntityA {
+int id_a1
+int id_a2
+String uuid_a1
+String code_a1
+String name_a1
+String type_a1
+bool flag_a1
}
class EntityB {
+int id_b1
+int ref_id_b1
+String uuid_b1
+String name_b1
+bool flag_b1
+String op_b1
}
EntityB --> "1" ExtrasB1
class ExtrasB1 {
+String? custom_b1_prop1
+String? custom_b1_prop2
+String model_b1
}
ExtrasB1 --> "1" InternalRefB1
class InternalRefB1 {
+String ref_code_b1_1
+String ref_code_b1_2
+int ref_id_b1_1
}
class EntityC {
+int id_c1
+int ref_id_c1
+int ref_id_c2
+String item_code_c1
+String name_c1
+String url_c1
+String op_c1
+bool flag_c1
}
EntityC --> "1" ExtrasC1
class ExtrasC1 {
+String? custom_c1_prop1
+float value_c1
+String media_flag_c1
+String content_flag_c1
}
class EntityD {
+int id_d1
+int ref_id_d1
+String name_d1
+String type_d1
}
class LinkEntityA {
+int id_la1
+int ref_id_la1
+int ref_id_la2
}
class MediaCollectionA
MediaCollectionA --> "*" MediaItemA
MediaCollectionA --> "*" int
class MediaItemA {
+int id_mia1
+int ref_id_mia1
+String url_mia1
+String type_mia1
}
MediaItemA --> "1" ExtrasMIA1
class ExtrasMIA1 {
+DateTime timestamp_mia1_1
+DateTime timestamp_mia1_2
+String name_mia1
+int size_mia1
}
class RuleItem {
+int id_rca1
+String type_rca1
+int ref_id_rca1
}
RuleItem --> "1" ExtrasRCA1
class ExtrasRCA1 {
+Map keywords_rca1
+bool? flag_rca1
}
In contrast, ChatGPT started to get confused with the MediaCollectionA part. It created an unrelated class called int (I'm not sure where it got that from), and then it also mishandled ExtrasRCA1, much like Gemini.
Comparing the two, I usually need fewer edits with Gemini, if any at all. Most of the time, Gemini gets it right, but there are also cases where I need some back and forth with both LLMs.
Mind you, I also tested researching code with an LLM, and based on my experience, the two are mostly the same in that department. My process involves searching for features (sometimes on a search engine), receiving feedback from the LLM, and then engaging in some back-and-forth before I do my own cross-checking to ensure its output is not a hallucination.
In that regard, both ChatGPT and Gemini are fine. I did not test vibe coding for the two, nor do I do vibe coding, but overall, in my use case of diagram conversion, Gemini comes out on top.
Lastly if you are wondering why I put my experience of diagram conversion in code generation it is because Mermaid is a code as a chart. In an essence what I am doing is just the same task as creating simple code.
Image Generation
I use image generation quite extensively, often to create avatars for a text-based game I play or for forum-based games like Fallensword. When it comes to pure base-to-image generation, I find the two to be equal.
Using this prompt:
Generate a new image
Create an image of a warrior, with magical artifacts, that just came back from an adventure and now visits back the king. The king must be at the back of the warrior and the warrior must be the center of the image.
The king is very far back
Add also audiences at the side, must be royal members of the castle
However, Gemini lacks the ability to refine its previous image generations, whereas ChatGPT is very good at it. This gap is more obvious when modifying non-AI images and having the AI reimagine them. For example, I might want to reimagine a personal photo of mine in a Studio Ghibli style.

You can even give ChatGPT mockups or wireframes of what you want to do with a detailed description and often times it ends up close if not exact with what you want it to be.

For my use case, what Gemini can do is fine, but for everything else, ChatGPT comes out on top when it comes to image generation.
Video Generation
ChatGPT itself cannot generate videos. For that, OpenAI offers a separate portal for image and video generation called Sora. Sora is actually very good; it has the same ability to use existing images as context, so you can do a lot with it.
I have reimagined a Studio Ghibli-style photo and animated it for everyone's entertainment. In other cases, the avatars I generated for the games I play ended up being animated (saved as APNGs).
However, there is one thing Gemini does (via its Veo engine) that Sora cannot: it can make characters speak. This can lead to very interesting sketches, as you can write a prompt that includes a person's dialogue and have them act it out.
Although I haven't tested this feature extensively, I did generate a few videos for a laugh with my friends. For example, we were discussing AI video generation when another friend tried to hijack the conversation by talking about the peach jam she was making. As a creative way to steer the discussion back on topic, I prompted Gemini, "A woman creating peach jam and saying, 'I created a peach jam using fake videos,'" which led to a funny eight-second clip.
I can imagine it being used for a movie or a short cutscene, although I did notice it's terrible for non-realistic videos—but then again, so is Sora.
That being said, the ability for characters in Gemini's videos to speak is very good, and for that, I will say Gemini comes out on top on this one.
Writing assistant
I use LLMs to revise or proofread what I've written, and I have been doing this for quite some time in situations such as writing emails or blog articles.
There are also cases where I ask an LLM to generate proposals for me from just bullet points. This is especially useful when someone asks for something as soon as possible, but I can't write it out at that moment. I can dictate the points via voice, have the AI generate a draft, and then just read it over once to make any revisions.
For this task, I even created a specific project on OpenAI, but I often find that the "Gem" I created with Gemini (their equivalent to OpenAI's GPTs) performs better for my use case.
Conclusion
Basing on my findings, I can say that Gemini seems to be the better AI for my use cases. It is better at coding, video generation and as a writing assistant. However even though Gemini performs better, I will not say that ChatGPT is terrible at it, afterall I have been using ChatGPT pro for quite some time now (almost a year to be exact).
Honestly, I wish I could have both, but due to budget constraints, I've decided to stick with Gemini. I will certainly miss the better image generation from ChatGPT, but aside from the better performance for my work use cases, I also get 2TB of storage bundled in. For me, that's quite a steal.